
TALLER |
|
|
El Procesador, el cerebro del ordenador I

En el anterior artículo vimos las placas base y su importancia dentro de un equipo, todo va conectado a esta e influirá en todos los componentes que se le pueden añadir y sus capacidades, de estas afirmaciones podemos establecer una analogía y decir que sería la columna vertebral de nuestro ordenador, ahora vamos a hacer otra analogía y veremos lo que sería su cerebro, nos referimos al procesador.
El procesador, CPU (Computer Processor Unit) por sus siglas en inglés, es la unidad de procesamiento central, de este componente podemos decir claramente que es el más importante de un ordenador, ya que los ordenadores funcionan mediante instrucciones y el procesador ejecuta la mayor parte de estas.
Como hemos visto hasta el momento, el factor de forma es crucial a la hora de seleccionar cualquier componente del ordenador y en el caso del procesador cada tipo lleva un sistema de conexión distinto al que llamamos Socket o zócalo, el cuál como ya vimos en el artículo anterior va soldado a la placa base y de ahí la importancia a la hora de elegir la placa adecuada compatible con un procesador determinado y su factor de forma correspondiente. Los principales fabricantes de procesadores o microprocesadores para ordenador son Motorola, Qualcomm, ARM, TSMC, Intel y AMD. 
Un poco de historia Intel Tiene el honor de ser la primera compañía de microprocesadores del mundo, fue fundada en 1968, Intel son las siglas de Integrated Electronic, la compañía comenzó su andadura fabricando memorias DRAM, SRAM, ROM y fue el 15 de noviembre de 1971 cuando lanzaron su primer microprocesador el Intel 4004 diseñado para la creación de una calculadora, este fue el primero de su estirpe que ha continuado hasta nuestros días. AMD Fue fundada en 1969, por aquellos años producían chips lógicos empezando en 1975 a producir Memoria RAM y en ese mismo año producirá su primer clon del microprocesador de Intel 8080 el cual desarrollaron mediante ingeniería inversa, hoy en día son uno de los más importantes fabricantes de CPUs, GPUs (procesadores para gráficos) chipsets y demás dispositivos semiconductores. 
Motorola La mítica marca fue fundada en 1928, el nombre de "Motorola" fue adoptado en 1947, aunque ya fue utilizado como marca comercial desde 1930 cuando desarrolla la primera radio para automóvil. Creadores también del primer walkie talkie de la historia para el ejército estadounidense a principios de la Segunda Guerra Mundial, su nombre siempre ha estado ligado al universo de las comunicaciones, desarrollando por ejemplo el primer teléfono móvil del mundo (DynaTAC). En el campo de la fabricación de semiconductores, pronto desarrolló toda clase de chips, incluyendo en la década de los 80 y 90 los circuitos integrados utilizados en los ordenadores de las familias Atari ST, Commodore Amiga, Apple Macintosh (Primer ordenador personal que triunfó frente a la hegemonía PC y permitió difundir la interfaz gráfica) y Power Macintosh, pues en aquella época equipó a la mayoría de rivales del IBM PC y compatibles. En el año 2003 Motorola anunció que escindiría la producción de semiconductores en la creación de una nueva empresa Freescale Semiconductor, Inc. ARM Es una de esas empresas jóvenes dentro del universo informático que ha conquistado un sitio preeminente en los últimos años, gracias a la pérdida de importancia del sector PC clásico. Todo surge de una pequeña compañía llamada Acorn Computers interesada en crear ordenadores baratos pensados para el sector educativo. Estos equipos debían como premisa básica, llevar en su interior por tanto un procesador lo más sencillo posible. Barato es sinónimo de pocos transistores por lo cual Acorn necesitaba tener una arquitectura con un número pequeño de instrucciones y que fueran sencillas. Dio la casualidad de que al hacerlo de esta manera creó un micro y una arquitectura que consumía muy poco lo cual hacía que fuera ideal para los futuros equipos móviles. Apple se alió con Acorn buscando un procesador para su proyecto Newton, una especie de PDA. De aquí surge el ARM610 y para ello se crea una nueva empresa denominada ARM para trabajar en el proyecto. Aunque el Newton fue un fracaso, significó la creación de una de las grandes empresas del sector de la informática móvil y computadoras personales bajo la premisa inicial de procesadores que manejaban un juego de instrucciones realmente simple que le permitía ejecutar tareas con un mínimo consumo de energía. Fue a partir del desarrollo del ARM8 cuando comenzó a usarse dentro de calculadoras, GPS y dispositivos móviles. Actualmente nos encontramos que muchos dispositivos móviles usan la familia Cortex de ARM. Los diseños de ARM se ha convertido en uno de los más usados alrededor del mundo y se encuentra presente en discos duros, juguetes, periféricos, móviles o tabletas. 
Tipos de socket Se conoce como socket o zócalo el lugar donde se inserta el microprocesador. Existen diferentes tipos según el método de sujeción que emplean y la configuración de los pines que lo forman. Esta segunda característica permite la compatibilidad de unos procesadores u otros con la placa base. Existen grupos diferenciados, según el fabricante del procesador sea AMD, Intel u otra. Por lo tanto, a la hora de elegir una placa u otra y un procesador hay que asegurarse que ambos dispositivos sean compatibles entre sí. Existen variantes desde 40 conexiones para integrados pequeños, hasta más de 1300 para microprocesadores, los mecanismos de retención del integrado y de conexión dependen de cada tipo de zócalo, aunque en la actualidad predomina el uso de zócalo con pines (Zero Insertion Force, ZIF) o LGA con contactos. El zócalo va soldado sobre la placa base de manera que tiene una conexión eléctrica directa con el circuito impreso. El procesador se monta referenciado por unos puntos de guía (borde de plástico, indicadores gráficos, pines o agujeros restantes) de manera que cada pin queda alineado con el respectivo punto del zócalo. También alrededor del área del zócalo, se crean espacios libres y se instalan elementos de sujeción y mecanismos, que permiten la instalación de dispositivos de disipación de calor, de manera que el procesador quede entre el zócalo y esos disipadores. PGA Pin Grid Array traducido como matriz de pines en cuadricula, en este sistema los pines (distintos conectores que sobresalen de un chip en forma de pequeñas agujas que se introducen en su correspondiente receptor hembra) A los pines que normalmente encontramos sobresaliendo de un procesador se encuentran en la parte inferior del chip, para conectarlo tendremos que hacer coincidir estos pines en el Socket con un tipo de mecanismo de inserción llamado Fuerza de Inserción Cero o ZIF estas siglas hacen referencia la cantidad de fuerza necesaria para conectar un procesador en su Socket. 
LGA, Land Grid Array o Matriz de contactos en cuadrícula, sistema donde al contrario que en el anterior los pines de conexión no los encontraremos en el procesador sino en el propio Socket de la Placa Base. 
BGA (ball grid array, matriz de rejilla de bolas): la conexión se realiza mediante pequeños pines en forma circular colocados en el zócalo, estas conexiones encajan a los orificios de la CPU y se fijan soldándolos. Adaptadores A veces, a pesar de las diferencias entre unos zócalos y otros, existe retrocompatibilidad (las placas bases aceptan procesadores más antiguos). En algunos casos, si bien no existe compatibilidad mecánica y puede que tampoco de voltajes de alimentación, sí en las demás señales lo que permite en teoría poder usarlos con pequeñas adaptaciones, por lo que existen adaptadores que permiten montar procesadores en placas con zócalos diferentes, de manera que se monta el procesador sobre el adaptador y éste a su vez sobre el zócalo. Comprendiendo cómo funciona la programación de instrucciones a nivel del procesador ¿Porqué de las diferentes arquitecturas? La programación de las primeras computadoras digitales se realizó mediante instrucciones consistentes en códigos numéricos que indicaban a los circuitos de la máquina los estados correspondientes a cada operación: el lenguaje máquina. Sin embargo, pronto los primeros usuarios de estas computadoras se dieron cuenta de la ventaja de escribir sus programas mediante claves mnemotécnicas, más fáciles de recordar que los códigos numéricos del lenguaje máquina. Estas claves constituyen el lenguaje ensamblador de la máquina. La utilización del lenguaje ensamblador hace la programación más sencilla, ya que el manejo de los códigos numéricos en forma de claves textuales hace más “humana” la programación, proporcionando un interfaz más amigable. El uso del lenguaje ensamblador para escribir un programa no penaliza de ninguna manera la eficiencia de ejecución del programa, dado que las claves mnemotécnicas tienen una correspondencia inmediata con un código numérico, por lo que puede decirse que el rendimiento es el mismo que si el programa se hubiera escrito directamente en lenguaje máquina. Sin embargo, la utilización del lenguaje ensamblador para escribir programas tiene ciertos inconvenientes, como son: - Falta de fiabilidad: Es frecuente que los programas, tanto de sistema como de aplicación, continúen mostrando nuevos errores después de años de funcionamiento. -Dificultad de mantenimiento: Si bien es complicado realizar cambios para el mantenimiento de grandes programas escritos en ensamblador, pasado cierto tiempo desde su escritura la complejidad aumenta exponencialmente, máxime si quien tiene que hacer los cambios no es el programador inicial. -Conocimiento de la arquitectura: Cada máquina posee un lenguaje ensamblador, y se requiere que el programador conozca previamente la arquitectura de la máquina. Obviamente esto condicionaba la complejidad de los desarrollos y su mantenimiento. Por ello, la respuesta desarrolló lenguajes de programación de alto nivel. Estos lenguajes de alto nivel (high-level language, HLL) permiten al programador expresar los algoritmos de manera más concisa y se encargan de buena parte de los pormenores. 
Sin embargo, desde la aparición de los primeros compiladores, la programación en ensamblador se siguió utilizando igualmente durante décadas. Incluso en sistemas complejos las zonas más críticas a veces se programan en lenguaje ensamblador. ¿Por qué? Desgraciadamente, la aparición del compilador como solución ocasiono otro problema, conocido como salto semántico: la diferencia entre las operaciones que proporcionan los lenguajes de alto nivel (HLL) y las que proporciona la arquitectura del computador. Los síntomas de este salto semántico incluían: -Ineficiencia de la ejecución. -Tamaño excesivo del programa compilado en lenguaje máquina. Estas desventajas se plasman, por ejemplo, en el hecho de que la eficiencia de un compilador estuviera muy por encima del 60% en las primeras décadas del uso de compiladores, lo cual quiere decir que, si el mismo programa se programaba en lenguaje ensamblador, se ejecutaba en aproximadamente la mitad de tiempo, necesitando el código menor cantidad de memoria. No resulta, pues, extraño, que el paso a la utilización del compilador no fuera inmediato. Obviamente, la solución a este problema pasaba por ‘cerrar el gap’, es decir, reducir y eliminar el salto semántico. Intentar que la eficiencia de ejecución y el tamaño del programa fuera la misma tanto si se programaba en ensamblador como si se programaba mediante un compilador. Por tanto, la solución de los diseñadores fueron arquitecturas que intentaban cerrar este hueco. Las arquitecturas propuestas incluían grandes conjuntos de instrucciones, decenas de modos de direccionamiento e incluso sentencias HLL implementadas en hardware (microprogramadas). Todas ellas arquitecturas CISC (Complexe Instruction Set Computer). Mientras tanto, durante algunos años se hicieron algunos estudios para determinar las características y patrones de ejecución de las instrucciones máquina generadas por programas escritos en HLL. 
Fueron los resultados de estos estudios los que originaron la búsqueda de una aproximación diferente, es decir, una arquitectura que diera soporte a los HLL de una forma más natural, intentando reducir al máximo posible el hueco. La comprensión de los resultados de estos estudios y de la forma que tienen los compiladores de gestionar las variables en pila llevó al desarrollo de la arquitectura RISC más sencilla y rápida. Con el paso del tiempo nuevos problemas en el rendimiento y la evolución en potencia y costes de producción se añadieron a la ecuación, así que estos dos diseños iniciales (CISC-RISC) han dado lugar a profundas evoluciones con el paso de los años que permiten acercamientos más ambiciosos para aprovechar el avance en potencia y rendimientos a precios más asequibles de las últimas décadas que nos han conducido a una rivalidad con nuevas ideas como VLIW o EPIC, siendo el momento actual una compleja mezcla de arquitecturas y “migraciones” siendo el ejemplo más conocido el paso en el sistema operativo Windows del x86 (16-32bits) al x64 (versión de 64 bits del conjunto de instrucciones x86). Tipos básicos de arquitecturas de procesador Por programa informático podemos entender un conjunto de instrucciones almacenadas en algún soporte, estas instrucciones al pasar por el procesador serán ejecutadas siguiendo un conjunto de instrucciones específicas, estas instrucciones que pueden ser de varios tipos definen en gran medida la arquitectura de un procesador, es decir la arquitectura lógica para poder interpretar las instrucciones. Hoy podemos distinguir entre cinco tipos de arquitecturas: arquitectura CISC (Complex Instruction Set Computer), que forma la base de todos los procesadores x86 o compatibles con Intel, arquitectura RISC (Reduced Instruction Set Computer) o que ejecuta un número limitado de instrucciones, arquitectura VLIW (Very Long Instruction Word) y la más cercana EPIC (Explicit Parallel Instruction Computing) o Instrucciones de computación explicitas en paralelo y DSP (Procesador Digital de Señales). La arquitectura CISC constituye el principal acercamiento histórico al concepto de microprocesador. Alcanza hasta la actualidad, presente en la serie x86, donde encontramos los procesadores fabricados por Intel, AMD o Cyrix. Esta arquitectura nace junto con el Intel 8086 en 1978, por aquella época la memoria del sistema era un bien costoso y los mayores sistemas sólo tenían unos pocos megabytes de memoria, así como los procesadores de los ordenadores personales unos pocos kilobytes. Así que la arquitectura CISC fue diseñada para reducir el uso de estos recursos. Sin embargo, el número de transistores de aquella época cuando se diseñó resulta incomparable con el actual número. Por ejemplo, el 8086 original contaba con 29000 transistores, en contraste con el Pentium 4 HT perteneciente a las últimas arquitecturas de la década pasada que tenía ya casi 6000 veces más, unos 167 millones. Así que entonces Intel eligió como solución de compromiso, la arquitectura CISC, aunque un cuarto de siglo más tarde carecía de mucho sentido las razones de aplicar esta arquitectura. Los procesadores aprovechando la arquitectura CISC pueden procesar instrucciones complejas, directamente “grabadas” en sus circuitos electrónicos. Esto significa que algunas instrucciones, dada su complejidad lógica son difíciles de cumplir por un microprograma con instrucciones básicas, se realizan por medio de hardware, es decir, son directamente programadas en el propio chip y pueden ser llamadas por macro comandos con el fin de ganar velocidad en la ejecución. 
Ahora bien, como podemos imaginar un microprocesador a nivel físico usa un limitado número de instrucciones microprogramadas fabricadas en silicio. Ya que no es posible desarrollar todas las instrucciones máquina en el procesador el procesador ejecuta las instrucciones máquina, que constituyen un lenguaje de comunicación con el microprocesador como una secuencia de instrucciones microprogramadas. Pero en oposición a la arquitectura CISC, un procesador basado en tecnología RISC no tiene incorporadas funciones avanzadas. Esta arquitectura anterior, creada en 1960 acorta y simplifica las instrucciones con igual longitud. Dado que el tiempo de ejecución de las instrucciones es idéntico al simplificar e igualar la longitud, es posible que estas instrucciones sean ejecutadas en paralelo, agrupando unos pocos buses de datos en una arquitectura común permitiendo una ejecución más rápida. Los procesadores más nuevos van aún más lejos, aplicando procesos de predicción al desarrollo del programa. De hecho, cuando un programa se encuentra con un ciclo condicional, es decir, una declaración del tipo “if, if not”, el proceso predice la forma en que el programa tendría mayor oportunidad de continuar y organizar la secuencia de instrucciones de esa manera. Si el procesador ha hecho una buena elección, es decir, lo que sucede estadísticamente entre el 80 y 90% de las veces, ya estaría por delante de algunas secuencias de instrucciones y habría ganado tiempo durante la ejecución con respecto al desarrollo normal. Si ha cometido un error, retrocedería, vaciando el bus de datos paralelo de la secuencia de instrucciones equivocadas y cargando las nuevas. Como hemos visto, a la hora de ejecutar un programa el procesador tiene que realizar cierto número de operaciones, mientras ejecuta unas las otras quedarían almacenadas en una memoria de alta velocidad llamada Caché A diferencia de la tecnología RISC, donde el procesador organiza las secuencias de instrucciones, en el modelo EPIC (Explicit Parallel Instruction Computing), el encargado es el compilador, responsable de optimizar el código a fin de tomar ventaja de la ejecución en paralelo. La arquitectura EPIC utiliza ambos principios de la arquitectura de super escala y el procesamiento en paralelo de datos. Los procesadores de 64 bits desde la generación Itanium, producidos por Intel, han tomado prestado la arquitectura EPIC, más exitosa que la ILP (Instruction Level Parallelism), desarrolladas conjuntamente por HP e Intel, por ejemplo. 
En los años 70 los procesadores se fabricaban en un proceso de 10 micrómetros, un tamaño que se reduciría a 3 µm en 1975 y a 1.5 µm en 1982. Sería a partir de 1989 cuando la evolución del tamaño de los chips caería por debajo de esta unidad de medida, pasando por los 800 nanómetros en ese curso a los 600 nm con los que se producían los chips en 1994 o los 350 nm de 1995. Ya en el nuevo milenio, la industria lograría fabricar procesadores de menos de 100 nm (90 nm en el año 2004). En 2006, se lograría alcanzar la meta de los 65 nanómetros, mientras que en 2008 se superaría la línea de los 45 nm. En 2012, el estándar se volvieron los 22 nanómetros, cifra superada en el año 2014 al alcanzarse los 14 nm. Fue Intel la que dio este paso en primer lugar, aumentando de forma notable el número de transistores por cada chip y, por ende, multiplicando el rendimiento. Como referencia, este fabricante estima que, entre la era de los 45 nanómetros y la de los 14 nm se ha duplicado el rendimiento de sus procesadores. Asimismo, con este cambio, los chips pasaron de tener un grosor de 26 mm en la era de los 22 nm a solo 7,2 mm con 14 nm., a finales de 2016 los fabricantes de procesadores estaban ya luchando para vencer la penúltima barrera, los 10 nanómetros y la carrera no acaba aquí:7 nanómetros: IBM, Samsung y TSMC ya han logrado producir chips de este tamaño.
La tecnología EPIC, ya presenté hoy en día, ofrece al compilador nuevas posibilidades para encontrar paralelismo entre las instrucciones. En muchas aplicaciones, especialmente en aplicaciones multimedia, se ejecutan un gran número de operaciones elementales, la clave del comportamiento de los microprocesadores está en lo que llamamos “paralelismo con un pequeño paso”. Esto significa ejecutar en paralelo el mayor número posible de instrucciones elementales. El concepto VLIW (very long instruction word) introduce una cuarta idea: reagrupamiento de un gran número de operaciones elementales independientes en una palabra de instrucción, que va a ser leída y ejecutada en un sólo ciclo de reloj. La arquitectura VLIW está basada en la ejecución de instrucciones, más complejas que con la estructura CISC. Mientras la arquitectura RISC consiste en la simplificación de la ejecución de instrucciones por su contracción, el concepto VLIW usa justamente el método opuesto: codificación de cuatro o más instrucciones en una palabra, es decir, una sola operación de máquina. DSP (Procesador Digital de Señales) Por otro lado, existen procesadores para funciones muy específicas donde podríamos destacar, los DSP o procesadores digitales de señal que son microprocesadores específicamente diseñados, como el nombre indica para el procesado digital de señales. Algunas de sus características más básicas como el formato aritmético, la velocidad, la organización de la memoria o la arquitectura interna hacen que sean o no adecuados para una aplicación en particular, ya que sus usos son muy específicos. Estrictamente hablando, el término DSP se aplica a cualquier chip que trabaje con señales representadas de forma digital. En la práctica, el término se refiere a microprocesadores específicamente diseñados para realizar procesado digital de señal. Los DSP utilizan arquitecturas especiales para acelerar los cálculos matemáticos intensos implicados en la mayoría de sistemas de procesado de señal en tiempo real. Por ejemplo, las arquitecturas de los DSP incluyen circuitería para ejecutar de forma rápida operaciones de multiplicar y acumular, conocidas como MAC. Por contra, los microprocesadores de propósito general o microcontroladores no están especializados para ninguna aplicación en especial, en el caso de los microprocesadores de propósito general, ni están orientados a aplicaciones de control, en el caso de los microcontroladores. Los procesadores DSP se utilizan en muy diversas aplicaciones, desde sistemas radar hasta la electrónica de consumo. Como es de suponer, ningún procesador satisface todas las necesidades de todas o la mayoría de aplicaciones. Así pues, el primer objetivo a cumplir a la hora de elegir un procesador DSP para un dispositivo concreto es ponderar la importancia relativa de las prestaciones, coste, integración, facilidad de desarrollo, consumo y otros factores para las necesidades de la aplicación en particular. Las grandes aplicaciones, en términos de dinero que mueven sus productos, se realizan para los sistemas pequeños, baratos y con un gran volumen de producción como los de telefonía celular, disqueteras y módems, en donde el coste y la integración son de la mayor importancia. En sistemas portátiles, alimentados por baterías, el consumo es crítico. Sin embargo, la facilidad de desarrollo es generalmente en estas aplicaciones menos importante para el diseñador. A pesar de que estas aplicaciones casi siempre implican el desarrollo de hardware y software a medida, el enorme volumen de producción justifica el esfuerzo extra de desarrollo. Una segunda clase de aplicaciones englobaría a aquellas que procesan un gran volumen de datos mediante algoritmos complejos. Ejemplos incluyen la exploración sonar y sísmica, donde el volumen de producción es bajo, los algoritmos más exigentes y el diseño del producto más largo y complejo. En consecuencia, el diseñador busca un DSP que tenga máximas prestaciones, buena facilidad de uso y soporte para configuraciones multiprocesador. En algunos casos, más que diseñar el propio hardware y software, el sistema se construye a partir de placas de desarrollo de catálogo y el software a partir de librerías de funciones ya existentes. 
VLIW y DSP Hablar de DSP obliga a hacer referencia a las nuevas arquitecturas VLIW (Very Long Instruction Word) que están siendo adoptadas por los DSP de muy altas prestaciones. Las Tecnologías de la Información y las Comunicaciones (TIC) demandan cada vez más recursos para poder procesar grandes volúmenes de datos. Hasta ahora, los avances en la capacidad de cómputo de los procesadores se han basado en el aumento dela velocidad del reloj y en innovaciones en la planificación, por parte del hardware, de la ejecución de instrucciones. Este modelo actual presupone que cada nueva generación de procesadores es capaz de ejecutar más instrucciones y será difícil que las arquitecturas tradicionales continúen doblando prestaciones cada 12-18 meses sin que se emigre a una nueva tecnología. El número de instrucciones por ciclo aumenta y también lo hace el número de interdependencias entre instrucciones a comprobar para determinar qué instrucciones pueden ejecutarse de forma simultánea. La lógica compleja requerida para la correcta planificación de instrucciones ocupa una gran parte del silicio del procesador y empieza a no tener sentido dedicar una gran parte de los recursos del procesador a la planificación de instrucciones. En su lugar, parece tener más sentido utilizar ese silicio para poder ejecutar más instrucciones por ciclo, incorporando más unidades funcionales y aumentar así el paralelismo de ejecución, mientras que la planificación de instrucciones se realiza por el compilador. Éste es el principio en que se basa la arquitectura VLIW. Esta reducción de complejidad, hardware más sencillo y menor número de transistores, permite incrementarla velocidad del reloj y al mismo tiempo reducir el consumo. El concepto de arquitectura VLIW comenzó en 1975 y desde entonces han ido apareciendo modelos en este diseño, pero siempre más a un nivel de prototipo que a nivel comercial. Sin embargo, no ha sido hasta hace relativamente pocos años, aproximadamente a finales del siglo XX, que los esfuerzos en la mejora del compilador, en aspectos de paralelismo ha hecho que estos procesadores sean realmente eficientes. Tradicionalmente, las ventajas asociadas con la arquitectura VLIW eran difíciles de conseguir y su futuro era cuestionable. La falta de compiladores eficientes a menudo significaba que el programador tuviera que pasar muchas horas tratando de optimizar, la mayoría de las veces sin éxito, su extenso código para mejorar las prestaciones de la aplicación. En una arquitectura VLIW, las instrucciones poseen un formato grande de palabra compuesto por múltiples instrucciones independientes que incluye un campo de control para cada una de las unidades de ejecución. El tamaño de la instrucción depende de dos factores: el número de unidades de ejecución disponibles y la longitud de código requerida para cada una de ellas. Una consecuencia de ello es que los buses internos de datos y de instrucciones son de mayor tamaño. Por otro lado, a diferencia de los procesadores superescalares en los que la planificación de las instrucciones para buscar el máximo paralelismo la realiza el propio procesador, en las arquitecturas VLIW esta tarea la realiza el compilador. Esta planificación es conocida como “static scheduling”. Una ventaja inmediata de este tipo de planificación es que permite dedicar más tiempo a encontrar la mejor optimización, aunque esto hace que el compilador sea más complejo ya que sobre él recae la responsabilidad de agrupar de la mejor forma posible las instrucciones. Arquitecturas VLIW y procesadores superescalares Las arquitecturas VLIW están estrechamente relacionadas con los procesadores superescalares. Ambos tratan de aumentar la velocidad computacional mediante paralelismo a nivel de instrucciones en el que se utilizan múltiples copias de algunas etapas de la “pipeline” o unidades de ejecución trabajando en paralelo. Las dos diferencias principales recaen en cómo se formulan las instrucciones y en cómo se realiza su planificación o secuenciamiento. 
Rendimiento de un procesador, factores reales y publicitados comercialmente A la hora de identificar la potencia real de un procesador hay varios factores a tener en cuenta, aunque en la práctica, no os vamos a engañar, es un galimatías indescifrable, lleno de datos publicitarios confusos que poco tienen que ver con la realidad, como habréis comprobado al ver las diferencias entre las diferentes arquitecturas hace un momento. Pero podemos tomar como referencia algunos valores y características que se publicitan, aunque antes de empezar ya os podemos garantizar que son puramente subjetivas, puesto que solo la suma de múltiples parámetros y la realización de complejas pruebas difíciles de evaluar os permitirán saber la potencia real de un procesador (además las diferentes empresas desarrolladoras de procesadores han aprendido a engañar a estos “benchmarks” o pruebas de rendimiento). Una vez advertidos veamos los factores más básicos y algunos ejemplos de cómo se publicitan estas tecnologías. El primer factor como acabamos de comentar es la arquitectura. En el segundo estaría la velocidad del procesador, esta se mide en ciclos por segundo: 1 megaherzios sería el equivalente a un millón de ciclos por segundo y un gigaherzio mil millones de ciclos por segundo. El tercer factor es la cantidad de datos que una CPU puede procesar a la vez, esto depende del tamaño del FSB (Front Side Bus), bus de la CPU o bus de datos del procesador, este indica la cantidad de datos que puede procesar a la vez, su tamaño se mide en bits ( recordemos un bit es la unidad mínima en informática los ordenadores reciben las instrucciones “traducidas” al lenguaje binario, esto quiere decir a 0 y 1, un bit sería un solo valor por ejemplo 0, un byte sería 8 bits). Sabiendo lo que es un bit los procesadores actuales usan un FSB de 32 bits o de 64 bits, actualmente podemos decir que los procesadores de 32 bits están desapareciendo para su uso en ordenadores personales (todavía no aplicaciones industriales o dispositivos de todo tipo) e igualmente los sistemas operativos están abandonando el soporte para 32 bits. 
¡Cuidado con las ventajas de rendimiento publicitadas! Ejemplos de los diferentes términos y “Tecnologías” con los que se anuncian los procesadores.
Los distintos fabricantes de procesadores a la hora de mejorar el rendimiento durante los años han utilizado distintas tecnologías a su vez que mejoraban la arquitectura y diseño, curiosamente tenían que resumirlas y simplificarlas a la hora de intentar vender sus procesadores al gran público (a veces inventándose directamente términos que poco tenían que ver con la arquitectura del procesador). Dependiendo del fabricante por ejemplo en Intel implementó la tecnología llamada hyperthreading por primera vez con los Pentium IV, esta tecnología se incorpora en algunos de sus procesadores, se basaba en ejecutar varios bloques de código o podríamos denominarlos subprocesos a la vez en un solo procesador, consiguiendo operar como si fueran dos procesadores, mientras que AMD usó la tecnología HyperTransport que es una conexión a muy alta velocidad y baja latencia entre el puente Norte (el puente Norte se explicó en el artículo anterior) y el procesador, consiguiendo de este modo una mejora en el rendimiento. Entre “mejoras” en la fabricación de procesadores se puede hablar del bit NX o bit de deshabilitación de ejecución, un sistema utilizado años atrás en procesadores Sun , Alpha de HP, PowerPC o IBM e incluso IA64 de Intel, el cual AMD renombró así y se comenzó a usar en procesadores más comunes, esta tecnología, Intel por su parte para desvincularse de su competidor lo llama XD bit, Execute Disable (Deshabilitar ejecución), esto empezó a ser compatible con Windows XP SP2 y Windows 2003 SP1, aunque para hacernos una idea del atraso de la tecnología de consumo con la profesional, Solaris lo soportaba diez años antes en procesadores SPARC, pero lo ha añadió activo por defecto en procesadores x86 a partir de Solaris 10. Aquí podemos ver como un ordenador de consumo que nos vendían como tecnología punta en su momento no era más que una adaptación de una tecnología de nada más y nada menos que una década de antigüedad. 
Su función es prevenir contra algunos tipos de Malware, esto se consigue al separar por un lado las instrucciones del procesador y por otro lado las relacionadas con el almacenamiento de datos, de este modo se evita que cierto software malicioso pueda conseguir provocar lo que se conoce como desbordamiento de búfer, esta función, cuando es compatible y está habilitada en el sistema operativo, puede proteger las áreas de la memoria que contienen archivos del sistema operativo contra ataques malintencionados con malware.
Gracias a los avances técnicos, la miniaturización…, los fabricantes de procesadores consiguieron sistemas que les permitieran al construir un chip de CPU el incorporar varios núcleos de CPUs. Esto es lo que se conoce por procesador de varios núcleos, que no es más que un chip que contiene dos o más procesadores dentro del mismo circuito integrado, consiguiendo con esta vía de integración, velocidades mayores entre los procesadores que si estos estuvieran conectados mediante una placa base, además de la velocidad que aumenta al repartirse las instrucciones entre varios núcleos, hoy en día lo normal en telefonía móvil, portátiles, sobremesa etc. Al igual que se comparten el “trabajo” (las instrucciones) entre los núcleos de CPU, el recurso de la RAM también se reparte entre estos, los procesadores multinúcleo se comenzaron a recomendar para aplicaciones con una gran carga de instrucciones como son la edición de video, videojuegos, etc.… Este nuevo modo de fabricación de procesadores hizo aumentar la potencia de los procesadores, lo que requirió un mayor consumo de energía, repercutiendo en el calor generado por el equipo y por lo tanto en la energía que debería ser evacuada de la caja o bastidor del PC, aunque en un principio estos conservarán mejor la energía y produjeran menos calor que sus homólogos de un núcleo. Overclocking o como prender fuego al procesador La técnica de overclocking se basa en aumentar el ciclo de reloj de un procesador de forma que este funcione a una velocidad mayor de la que se especificó, algunos procesadores especifican hasta cuanto se puede overclockear, si bien no es un método muy seguro para aumentar el rendimiento de un ordenador, dado que un aumento en los ciclos provocará mayor calor y mayor fatiga en los componentes disminuyendo la vida útil de este pudiendo llegar a “quemarlo”. 
2007 Taipéi IT Month: Intel Taiwan Overclocking Live Test Tournament. La excentricidad llevada al límite para realizar overclocking, en este caso enfriando el procesador con nitrógeno líquido.
En contraste, con el overclocking también podemos controlar esa velocidad y bajarla, de este modo el procesador no se calentaría tanto mejorando la fiabilidad y reduciendo el consumo energético. Esta práctica por tanto es típica en equipos portátiles y dispositivos móviles alargando así la duración de la batería. Tendencias tecnológicas y comerciales actuales, modelo evolutivo Tick-Tock de Intel Alrededor del año 2007 Intel adopta lo que se podía llamar un modelo evolutivo de sus chips, al que se llamaría Tick-Tock. Con esto se buscaba que cada “Tick” o ciclo de diseño y producción fuera una “contracción”, miniaturización de la tecnología anterior y cada “Tock” sería una evolución, una nueva microarquitectura. Para seguir una sola línea de evolución y ser conscientes de la velocidad que está cogiendo este mundo hemos escogido como ejemplo este caso de Intel: En agosto de 2015 Intel lanza los procesadores de microarquitectura Sky Lake la 6ª generación de procesadores con frecuencias de reloj a 4,5 GHz. Un año después en 2016 nace Kaby Lake la 7ª generación, la cual mantiene la medida de su predecesor de 14 nanómetros, esta medida hace referencia al tamaño de fabricación del semiconductor y hace referencia al tamaño de sus componentes que son una 14 milmillonésima parte de un metro. En agosto de 2017 se presenta la actualización de Kaby Lake Refresh que sería la octava generación de procesadores. Hay mejoras de velocidad de reloj y frecuencias “turbo”, más rápidas, aunque apenas hay mejoras en el rendimiento por MHz con su anterior versión Sky Lake, las nuevas generaciones añaden soporte para USB 3.1 generación 2 con velocidades que llegan a los 10 GBits y una arquitectura nueva de gráficos para 3D y video 4K añadiendo a su vez soporte nativo HDCP 2.2 High-Bandwidth Digital Content Protection, un tipo de gestión digital de derechos. 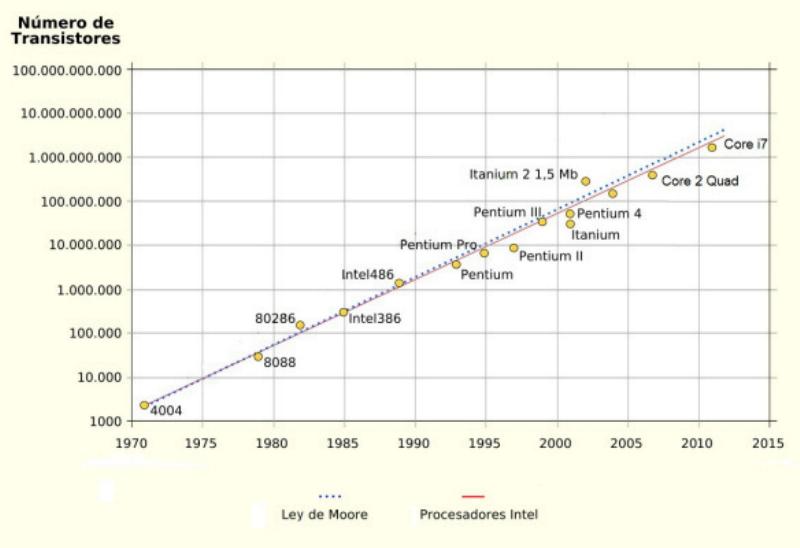
En 1965, Gordon Moore enunció la ley que lleva su nombre y que marcaría la tecnología y su desarrollo hasta nuestros días. Moore era un joven ingeniero que trabaja como director de los laboratorios de Fairchild Semiconductor durante los primeros tiempos de la microelectrónica (más tarde fue uno de los cofundadores de Intel). Para 1965, la industria se hallaba en pañales, pero en ebullición. En ese contexto, Moore observó que el número de transistores por unidad de superficie en los circuitos integrados se duplicaba cada año. Más tarde, en 1975, modificó su estimación a cada dos años. Esto era sólo una observación empírica de lo que se podía apreciar y no una ley rigurosa. Sin embargo, transcurridos casi 50 años, la ley no ha dejado de verificarse. En 1971 se creó el microprocesador, que es un chip que funciona como la unidad central de procesamiento de una computadora. El primer microprocesador fue el 4004 de Intel y desde ese momento los procesadores aumentan su potencia siguiendo la ley de Moore. En una gráfica de escala exponencial (en el eje vertical los valores se van multiplicando por 10) se ve como la evolución de los procesadores Intel sigue casi exactamente lo predicho por Moore. Todo este proceso es el que explica cómo las computadoras son cada vez más y más potentes, aunque el precio sea siempre el mismo. Y qué tecnologías que en un momento son muy caras, en pocos años se hagan accesibles para todos. La ley de Moore resultó ser más certera de lo que cualquiera pudo imaginar en 1965 y, contra cualquier pronóstico, se viene cumpliendo desde que fue enunciada hace medio siglo. Sin embargo, está por llegar a su fin. Esto es algo esperable ya que nada se puede reducir indefinidamente: si ninguna otra cosa sucede antes, al final nos topamos con el tamaño de un átomo, por debajo del cual no se pueden achicar más los transistores. En 2007, el propio Moore afirmó que su ley se mantendría vigente por otros 10 o 15 años, es decir hasta aproximadamente 2020. Dante Tomás Guvi
Y ahora le llegaría el turno a Coffe Lake la octava generación de Intel pasa del “quad core” es decir, de cuatro núcleos al “six core” con nuevos procesadores de seis núcleos así, hasta llegar a septiembre de 2018 cuando se supone saquen los nuevos Coffe Lake de 8 núcleos o Coffe Lake Refresh. Vamos, que alguien en los últimos años ha presionado el botón de “avance rápido” y esto parece no parar de avanzar a toda velocidad en una carrera loca, por eso es importante entender las características de nuestro equipo y con un poco de sentido común elegir las mejores opciones para nuestro equipo de manera que podamos estirar la vida de nuestro equipo el mayor tiempo posible. Te puede interesar:
Autor: Rubén Luna S.
Temas relacionados: Taller De Informática, CiberSeguridad, Taller, Rubén Luna S. , Informática. Reconocimientos y más información sobre la obra gráfica ADVERTENCIA: En este foro, no se admitirán por ninguna razón el lenguaje soez y las descalificaciones de ningún tipo. Se valorará ante todo la buena educación y el rigor sobre el tema a tratar, así que nos enorgullece reconocer que rechazaremos cualquier comentario fuera de lugar.
0 Comentarios
Deja una respuesta. |


Ciencia y Tecnología




Investigación Médica y Salud


Eres Periodista Científico?
Educación y Formación








Sociedad, Igualdad y Sostenibilidad





Cultura y Ocio






¿Tienes una cita?
Aventura y Supervivencia



|






